List of Regularly Used Data Tables In Augur
This is a list of data tables in augur that are regularly used and the various tasks attached to them.
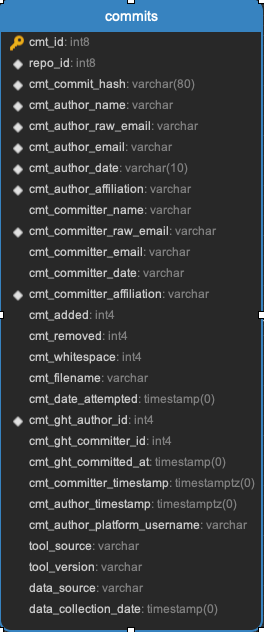
Commits
This is where a record for every file in every commit in every repository in an Augur instance is kept.
Task: Facade tasks collect, and also stores platform user information in the commits table.
Contributor_affiliations
A list of emails and domains, with start and end dates for individuals to have an organizational affiliation.
Populated by default when augur is installed
Can be edited so that an Augur instance can resolve a larger list of affiliations.
These mappings are summarized in the
dm_*tables.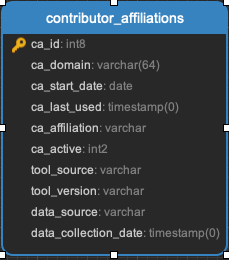
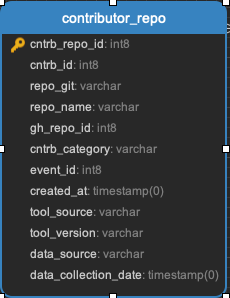
Contributor_repo
Storage of a snowball sample of all the repositories anyone in your schema has accessed on GitHub. So, for example, if you wanted to know all the repositories that people on your project contributed to, this would be the table.
contributor_breadth_model populates this table
Population of this table happens last, and can take a long time.
Contributors
These are all the contributors to a project/repo. In Augur, all types of contributions create a contributor record. This includes issue comments, pull request comments, label addition, etc. This is different than how GitHub counts contributors; they only include committers.
Tasks Adding Contributors:
Github Issue Tasks
Pull Request Tasks
GitLab Issue Tasks
GitLab Merge Request Tasks
Facade Tasks
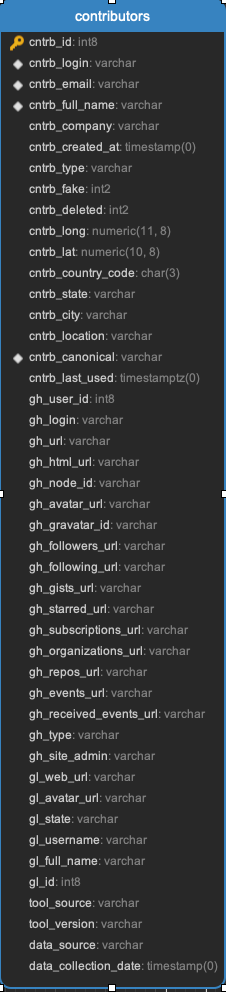
Contributors_aliases
These are all the alternate emails that the same contributor might use. These records arise almost entirely from the commit log. For example, if I have two different emails on two different computers that I use when I make a commit, then an alias is created for whatever the 2nd to nth email Augur runs across. If a user’s email cannot be resolved, it is placed in the unresolved_commit_emails table. Coverage is greater than 98% since Augur 1.2.4.
Tasks:
Facade Tasks
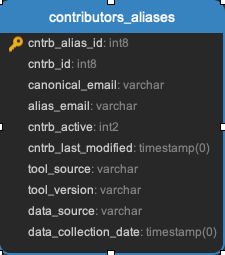
Discourse_insights
There are nine specific discourse act types identified by the computational linguistic algorithm that underlies the discourse insights task. This task analyzes each comment on each issue or pull request sequentially so that context is applied when determining the discourse act type. These types are:
negative-reaction
answer
elaboration
agreement
question
humor
disagreement
announcement
appreciation
Tasks:
Discourse Insights Task
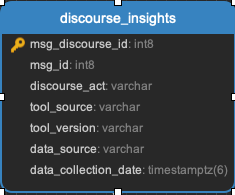
issue_assignees || issue_events || issue_labels
Task:
Github or Gitlab Issues Task
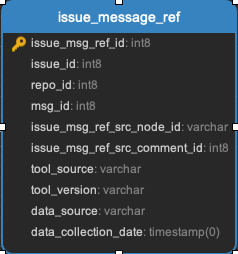
issue_message_ref
A link between the issue and each message stored in the message table.
Task:
Github or Gitlab Issues Task
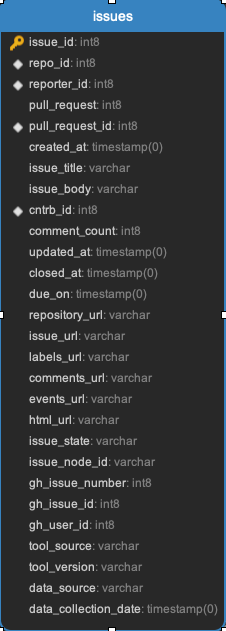
issues
Is all the data related to a GitHub Issue.
Task:
Github or Gitlab Issues Task
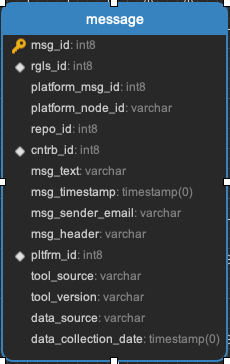
Message
Every pull request or issue related message. These are then mapped back to either pull requests, or issues, using the __msg_ref tables
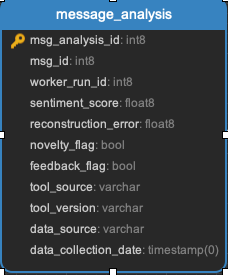
Message_analysis
Two factors evaluated for every pull request on issues message: What is the sentiment of the message (positive or negative), and what is the novelty of the message in the context of other messages in that repository.
Task:
Message Insights Task
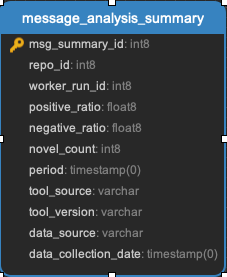
Message_analysis_summary
A summary level representation of the granular data in message_analysis.
Task:
Message Insights Task
Platform
Reference data with two rows: one for GitHub, one for GitLab.
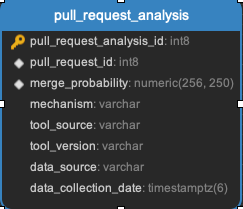
Pull_request_analysis
A representation of the probability of a pull request being merged into a repository, based on analysis of the properties of previously merged pull requests in a repository. (Machine learning tasks)
Task:
Pull request analysis task
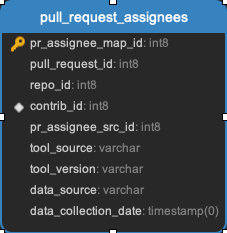
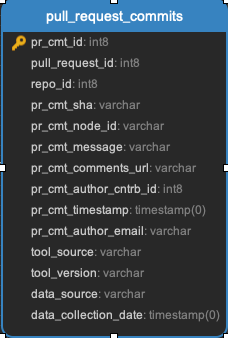
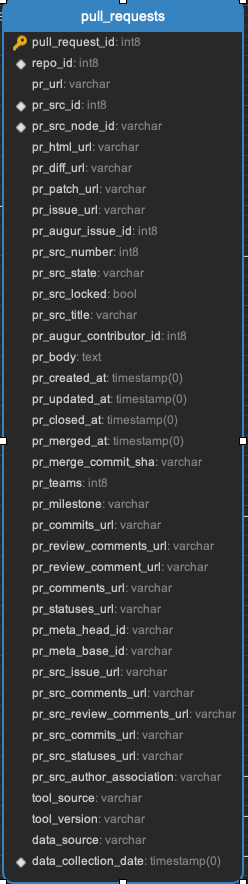
pull_request_assignees || pull_request_commits || pull_request_events || pull_request_files || pull_request_labels || pull_request_message_ref
All the data related to pull requests. Every pull request will be in the pull_requests data.
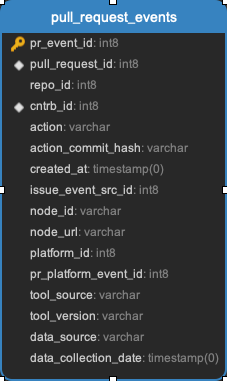
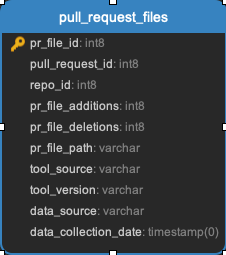
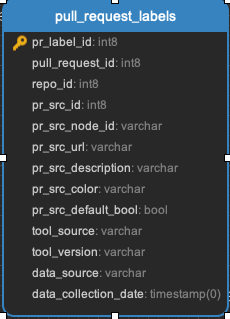
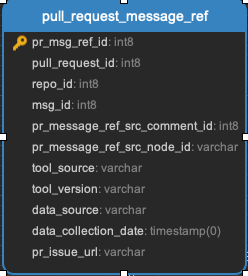
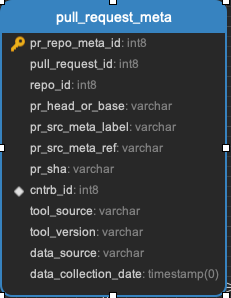
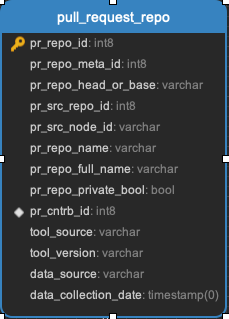
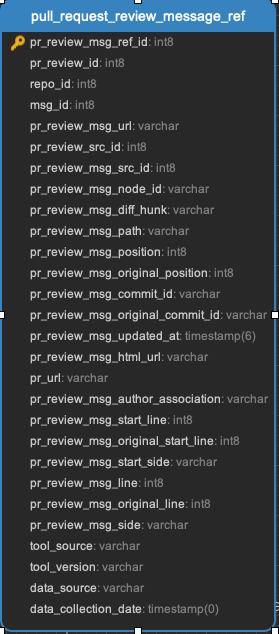
pull_request_meta || pull_request_repo || pull_request_review_message_ref || pull_request_reviewers || pull_request_reviews || pull_request_teams || pull_requests
All the data related to pull requests. Every pull request will be in the pull_requests data.
Releases
Github declared software releases or release tags. For example: https://github.com/chaoss/augur/releases
Task:
Release Task.
Repo
A list of all the repositories.
Repo_badging
A list of CNCF badging information for a project. Reads this api endpoint: https://bestpractices.coreinfrastructure.org/projects.json
Repo_cluster_messages
Identifying which messages and repositories are clustered together. Identifies project similarity based on communication patterns.
Task:
Clustering task
Repo_dependencies
Enumerates every dependency, including dependencies that are not package managed.
Task:
process_dependency_metrics
Repo_deps_libyear
(enumerates every package managed dependency) Looks up the latest release of any library that is imported into a project. Then it compares that release date, the release version of the library version in your project (and its release date), and calculates how old your version is, compared to the latest version. The resulting statistic is “libyear”. This task runs with the facade tasks, so over time, you will see if your libraries are being kept up to date, or not.
- Scenarios:
If a library is updated, but you didn’t change your version, the libyear statistic gets larger
If you updated a library and it didn’t get older, the libyear statistic gets smaller.
Task:
process_libyear_dependency_metrics
Repo_deps_scorecard
Runs the OSSF Scorecard over every repository ( https://github.com/ossf/scorecard ) : There are 16 factors that are explained at that repository location.
Task:
process_ossf_scorecard_metrics
Repo_groups
Reference data. The repo groups in an augur instance.
Repo_info
This task gathers metadata from the platform API that includes things like “number of stars”, “number of forks”, etc. AND it also gives us : Number of issues, number of pull requests, etc. .. THAT information we use to determine if we have collected all of the PRs and Issues associated with a repository.
Task:
repo info task
Repo_insights
Task:
Insight task
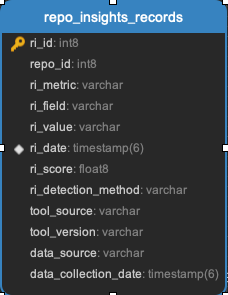
Repo_insights_records
Task:
Insight task
Repo_meta
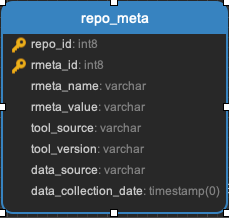
Exists to capture repo data that may be useful in the future. Not currently populated.
Repo_sbom_scans
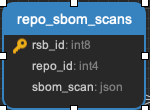
This table links the augur_data schema to the augur_spdx schema to keep a list of repositories that need licenses scanned. (These are for file level license declarations, which are common in Linux Foundation projects, but otherwise not in wide use).
Repo_stats
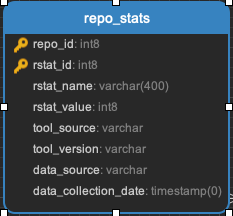
Exists to capture repo data that may be useful in the future. Not currently populated.
Repo_topic
Identifies probable topics of conversation in discussion threads around issues and pull requests.
Task:
Clustering task
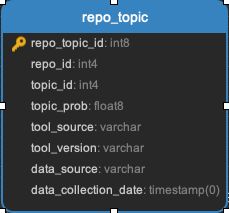
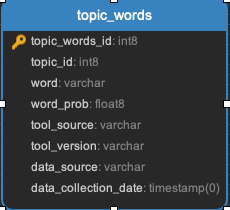
Topic_words
Unigrams, bigrams, and trigrams associated with topics in the repo_topic table.
Task:
Clustering task
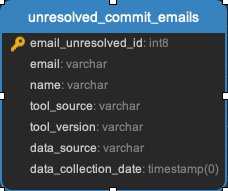
Unresolved_commit_emails
Emails from commits that were not initially able to be resolved using automated mechanisms.
Task:
Facade Tasks.